Abstract
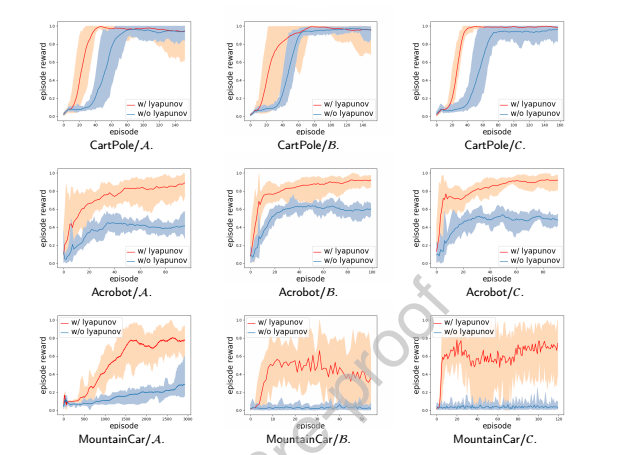
Reinforcement learning (RL) suffers from the designation in reward function and the large computational iterating steps until convergence. How to accelerate the training process in RL plays a vital role. In this paper, we proposed a Lyapunov function based approach to shape the reward function which can effectively accelerate the training. Furthermore, the shaped reward function leads to convergence guarantee via stochastic approximation, an invariant optimality condition using Bellman Equation and an asymptotical unbiased policy. Moreover, sufficient RL benchmarks have been experimented to demonstrate the effectiveness of our proposed method. It has been verified that our proposed method substantially accelerates the convergence process as well as improves the performance in terms of a higher accumulated reward.